Android SQLite Insertion Optimization
Preface
Recently, I've been working on a technical story which inserts more than 100,000 records at startup. The whole application relies on these data, so I have to make the insertion synchronous, before it complete, no function is available, all things the user could see is a loading page.
Inserting a single record with SQLiteDatabase.insert() takes about 20ms on my phone, 100,000 records would take 2000s. Blocking users at loading page for over half an hour is unacceptable. We have to reduce the time to a tolerable one.
Transaction
No changes can be made to database without transaction. Basically, any SQL command except SELECT will begin a transaction automatically if no one is in effect. In the worst case, inserting 100,000 records requires 100,000 transaction. Committing a transaction consists of several write() and fsync() calls. It's an expensive operation, we have to reduce the frequency of transaction committing.
I wrapped those 100,000 insert statement in one transaction. The insertion time has a significant change. It takes 18500ms on average to insert 100,000 records. Could I make it faster?
Prepared Statement
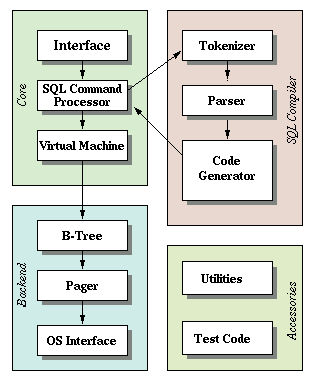
SQL statement will be compiled into VDBE code and handled to the virtual machine. SQLite provide a routine sqlite3_prepare_v2() to do the compilation. As we can see from the block diagram, the compiler has to tokenize the SQL statement first, then the parser need to assign meaning to those tokens and assemble them together. At last, the parser will call the code generator to produce VDBE code. It's not an easy task. So what happened when we call the SQLiteDatabase.insert() method? I took a snippet from Android source code, when SQLiteDatabase.insert() is called, it eventually gets here.
public long insertWithOnConflict(String table, String nullColumnHack,
ContentValues initialValues, int conflictAlgorithm) {
acquireReference();
try {
StringBuilder sql = new StringBuilder();
sql.append("INSERT");
sql.append(CONFLICT_VALUES[conflictAlgorithm]);
sql.append(" INTO ");
sql.append(table);
sql.append('(');
Object[] bindArgs = null;
int size = (initialValues != null && initialValues.size() > 0)
? initialValues.size() : 0;
if (size > 0) {
bindArgs = new Object[size];
int i = 0;
for (String colName : initialValues.keySet()) {
sql.append((i > 0) ? "," : "");
sql.append(colName);
bindArgs[i++] = initialValues.get(colName);
}
sql.append(')');
sql.append(" VALUES (");
for (i = 0; i < size; i++) {
sql.append((i > 0) ? ",?" : "?");
}
} else {
sql.append(nullColumnHack + ") VALUES (NULL");
}
sql.append(')');
SQLiteStatement statement = new SQLiteStatement(this, sql.toString(), bindArgs);
try {
return statement.executeInsert();
} finally {
statement.close();
}
} finally {
releaseReference();
}
}
SQLiteStatement is a wrapper class for native prepared statement. SQLite need to compile the same SQL statement 100,000 times! It doesn't make sense. So I build the corresponding SQLiteStatement in advance, and bind the parameters to the SQLiteStatement. Now the SQLite doesn't need to recompile SQL statement. I have made the insertion time even shorter, it's 5850ms on average now.
Enable Write-Ahead Logging
By default, SQLite ensure the consistency of database transaction by rollback journal. Generally, a transaction consists of the following steps:
- Acquire SHARED lock of database. The program needs to know the schema and the position to write before starting a transaction. If one database connection gets SHARED lock, all write requests to the database will be blocked, while other connection can still read data from the database.
- Read data from database. Read operation is achieved by system call, the data will be copied from kernel space to user space.
- Acquire RESERVED lock of database. Only one connection can acquire RESERVED lock at the same time. RESERVED lock can coexist with SHARED lock. Any connection with SHARED lock can still read from database, and any connection is capable of acquiring new SHARED lock too. The connection with RESERVED lock can write data to the user space memory, but not to the disk.
- Create rollback journal and backup original data to the journal file.
- Write data to user space buffer.
- Sync the rollback journal file to disk by fsync() call.
- Acquire PENDING lock of database. SHARED lock is allowed to coexist with PENDING lock, existing connection with SHARED lock can still read data, but no connection is allowed to get new SHARED lock. The PENDING lock will wait other connections to release SHARED locks.
- Once no SHARED lock is held, the PENDING lock will upgrade to EXCLUSIVE lock. Only one EXCLUSIVE lock is allowed on the file and no other locks of any kind are allowed to coexist with an EXCLUSIVE lock.
- Write user space buffer to kernel space.
- Sync database file to disk by fsync() call.
- If the synchronization succeed, delete the rollback journal file.
- Release locks.
A transaction requires two write() calls and two fsync() calls. We can also know that read and write operation can not be parallel in rollback journal mode. Write operations have to wait read operations to complete before it start.
Beginning with SQLite version 3.7.0, it provide "Write-Ahead Log(WAL)" option. Unlike traditional rollback journal mode, WAL write changes to a new WAL file, and keep the original content in database file. Thus read and write operation can be parallel.
When a read operation begins in WAL mode database, the reader will get an "end mark" from WAL file, the "end mark" is the position of last valid commit record. The reader first looks for the page in WAL file, if the page appears prior to the "end mark", it pulls the last copy of the page, otherwise it will looks for the page in original database file.
The pages modified in WAL file have to be transferred to original database eventually. This operation is called checkpoint. When the page size reaches checkpoint, WAL file will be synced to disk first, then the content in WAL file will be moved to original database file, database file will be synced to disk, and finally the WAL file will be reset. By default, the automatic checkpoint threshold is 1000 pages, program can change this value or disable the automatic checkpoint.
Checkpoint can run concurrently with read operation, while if checkpoint reaches a page that past end mark of any readers, it has to stop, otherwise it may overwrite the content that readers are actively using. The checkpoint will start from where it stopped on next write transaction. Usually, the WAL file will not be deleted, SQLite just rewind to the beginning and overwrite the file.
By default, the synchronous mode is FULL, it will cause a disk synchronization on every transaction commit. On WAL mode, NORMAL level synchronization would be enough. The disk synchronization only occurs on checkpoint. However you will lost all transactions since last checkpoint on power failure or application crash.
I enable the WAL mode by SQLiteDatabase.enableWriteAheadLogging() and set synchronous level to NORMAL. The insertion time has been reduced to 5257ms on average now!
Memory journal with synchronization OFF
Could it be even faster? Of course yes, but it's a little risky. We could keep the rollback journal file only in memory and turn off the synchronization.
database.execSQL("PRAGMA synchronous = OFF");
database.execSQL("PRAGMA journal_mode = MEMORY");
Now SQLite will not wait for disk synchronization, it just handle the data to system and continue, it may be magnitude faster than FULL mode on some circumstances. And the rollback journal file is kept in memory now, we save the time of disk I/O. While if we suffered power failure or application crash in the middle of a transaction, the database is very likely to corrupt. The insertion time is 4036ms on average with these settings.
Summary
Memory-Mapped I/O is also supported by SQLite, but the performance didn't seem to increase on Android. So I didn't mention it. Finally I enabled WAL mode and use NORMAL synchronous level. It's a compromise between data safety and performance. We're able to deal with 17000 insertion per second.